I've sat through dozens of meetings in the cloud era where someone waved their hands around, talking about the importance of being "multi-cloud," ready to flip a switch at the first sign of trouble in us-east-1. The result of these conversations is always a whiteboard that looks like it was just pulled from a conspiracy theorist's basement, and no concrete deliverables. For the teams I work with, optimizing a deployment strategy across a single cloud provider is enough of a stretch. Figuring out how to duplicate every moving part across multiple providers and regions is the type of thing that companies our size just can't pull off. But it doesn't stop the boss from dreaming about it.
Early in the morning (US time) on Tuesday, November 18, 2025, a small change to Cloudflare's database permissions caused the size of a file to double, exceeding its configured size limit. That file then propagated across Cloudflare's network, causing a widespread outage that took down a significant portion of the internet. And then my phone rang.
The Cloudflare outage of November 18 provided me with the perfect object lesson in the futility of any effort by an SMB to harden its application against an outage at a major cloud provider. One of my clients in the US had gotten up early to prepare a big email outreach, and just as he hit the send button, he received a notification that the site was down. Since his entire development team was in the US and still asleep, he called me, hoping I could help. And I did, but not in the way he wanted or expected.
This marketing campaign was the fruit of months of labor. It was in support of the next evolution of their primary product, one that would reduce operational cost, increase margin, and (if early feedback was to be believed) delight their customers. The start date of the campaign was carefully chosen to spread traffic across four days, while reaching every customer before their inboxes shift to Black Friday mode next week. The timing of this outage couldn't possibly have been worse.
I told him to log into the CRM and pause the email campaign. Then I told him to log into all of the places where he had set up ads and pause those as well. The first task was easy. The second proved to be tricky, but that actually made the rest of my job a lot easier. In almost every case, when he tried to log in to pause an ad campaign, the platform where the campaign was supposed to be running was also down. He started to recognize the scope of the outage and it stopped feeling so much like his site was down and more like the internet itself was down.
When he asked what was next, I suggested that he should go out for a nice filling breakfast and a good coffee. There wasn't anything else to do. I'd keep an eye on the network and text him when things came back online. He didn't like that answer. He wanted to "route around Cloudflare."
This client is a semi-technical founder, so I had to say a little more than "that's probably not a good idea" in order to get him on board with my breakfast plan. The first thing I pointed out was that Cloudflare manages the domain's name servers. Obviously, pointing a domain's name servers at a different provider comes with propagation delays, so even if there were no other holes in the plan, just this part could easily cause the migration to last longer than the outage he was trying to circumvent. Then there's the fact that Cloudflare was chosen for a reason, and one of those reasons was the caching that allows us to run big marketing campaigns like the one he's trying to launch. So we'd have to accommodate that another way.
I started looking through the list of external providers that the app relies on, trying to get a sense of how well they were holding up during the outage, and hoping to build my "just wait it out" case a little stronger. While I was doing that, he was attempting to top up an OpenAI account with more credits using a Mercury credit card. This mundane, totally unrelated activity of his finished the job for me. The transaction kept declining because, while OpenAI's site was up and their billing provider was up, Mercury's endpoint for authorizing transactions was down. It apparently relies on Cloudflare, so it was declining every attempted transaction as a reasonable (if annoying) fallback.
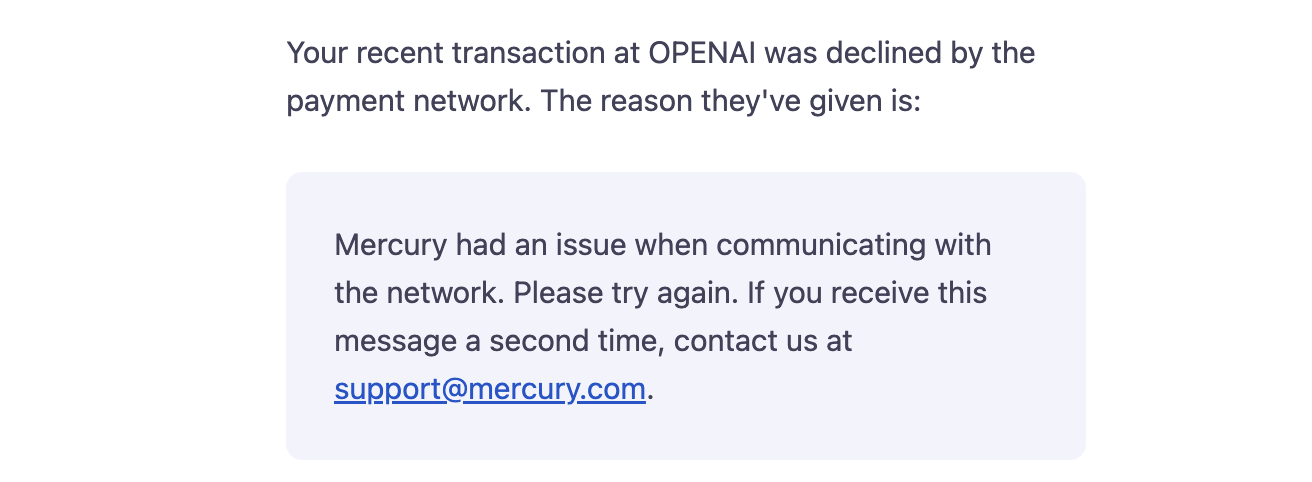
He realized in that moment that it was better to be one of the countless sites displaying a Cloudflare error page than a site that was apparently working but, due to some downstream dependency on something that needs Cloudflare, was broken in some harder-to-explain way. So he went out and had that breakfast. I texted him about an hour and a half later to say everything was back to normal, and he turned the marketing campaign back on. His day one sales exceeded expectations.
Much has been said and written about the danger of centralization and our dependency on a single point of failure, but there's no really clear path to solving that on a broad scale. Even as individual applications either successfully navigate complex, failure-resistant, multi-cloud deployments or leave the cloud entirely, nobody fully powers their entire application alone. Payment gateways, CDNs, analytics providers, and all of the other things that we choose to buy instead of build saddle us with their own failure points.
The reality is that global or even regional outages that span multiple services are vanishingly rare. We've had two in the past month, so it doesn't feel that way. But unless your business is providing an SLA, the right move for your company is almost certainly to put your fate in the hands of one of the big providers and trust them to keep these events to a minimum. And even if you are providing an SLA, you probably can't do better on your own than Cloudflare or AWS.
Well, you might be able to beat us-east-1.